Publications
* indicates equal contribution.
2025
- ICCV 2025
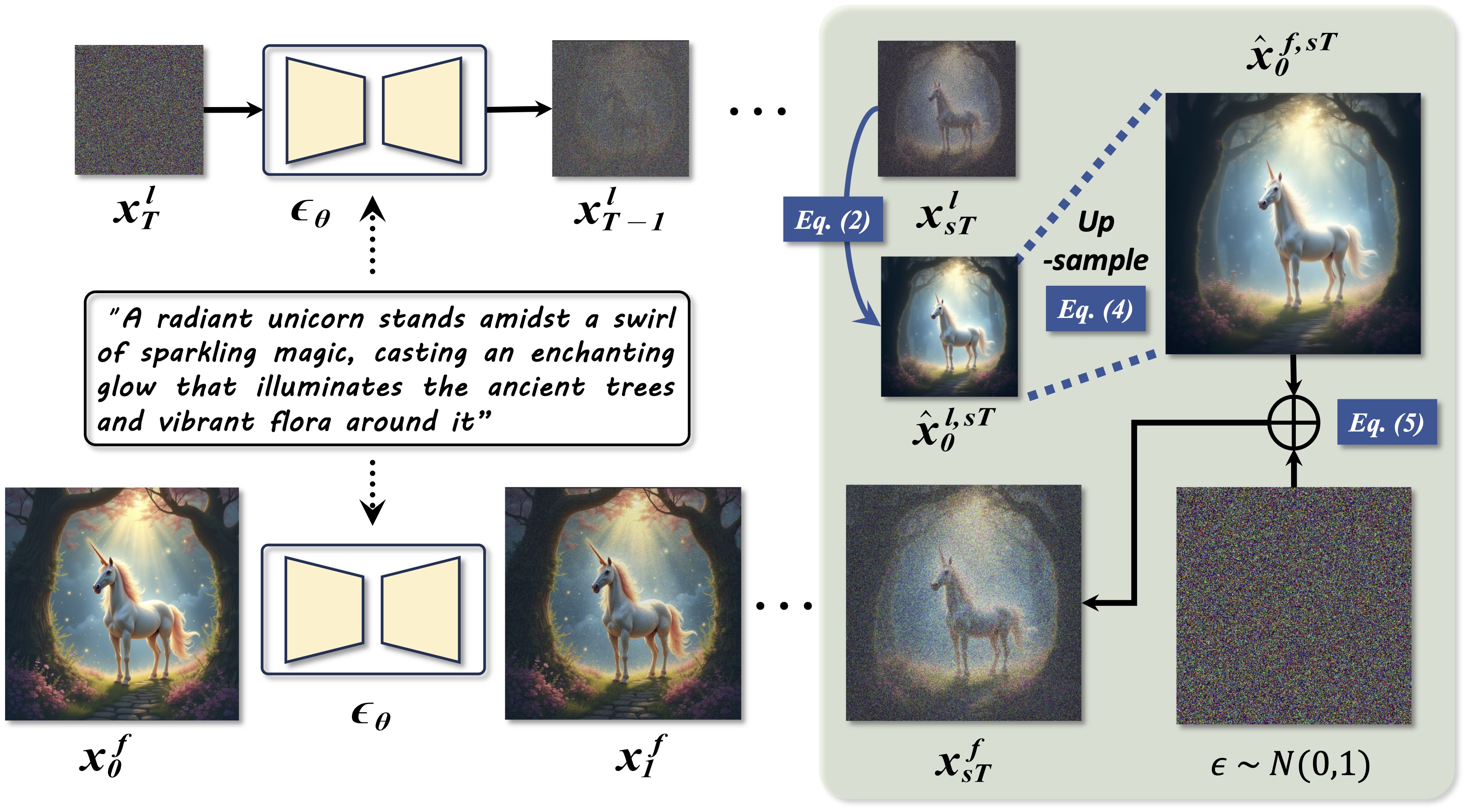 Fewer Denoising Steps or Cheaper Per-Step Inference: Towards Compute-Optimal Diffusion Model DeploymentZhenbang Du*, Yonggan Fu*, Lifu Wang*, Jiayi Qian, Xiao Luo, and Yingyan LinIn Proceedings of the International Conference on Computer Vision, 2025
Fewer Denoising Steps or Cheaper Per-Step Inference: Towards Compute-Optimal Diffusion Model DeploymentZhenbang Du*, Yonggan Fu*, Lifu Wang*, Jiayi Qian, Xiao Luo, and Yingyan LinIn Proceedings of the International Conference on Computer Vision, 2025Diffusion models have shown remarkable success across generative tasks, yet their high computational demands challenge deployment on resource-limited platforms. This paper investigates a critical question for compute-optimal diffusion model deployment: Under a post-training setting without fine-tuning, is it more effective to reduce the number of denoising steps or to use a cheaper per-step inference? Intuitively, reducing the number of denoising steps increases the variability of the distributions across steps, making the model more sensitive to compression. In contrast, keeping more denoising steps makes the differences smaller, preserving redundancy, and making post-training compression more feasible. To systematically examine this, we propose PostDiff, a training-free framework for accelerating pre-trained diffusion models by reducing redundancy at both the input level and module level in a post-training manner. At the input level, we propose a mixed-resolution denoising scheme based on the insight that reducing generation resolution in early denoising steps can enhance low-frequency components and improve final generation fidelity. At the module level, we employ a hybrid module caching strategy to reuse computations across denoising steps. Extensive experiments and ablation studies demonstrate that (1) PostDiff can significantly improve the fidelity-efficiency trade-off of state-of-the-art diffusion models, and (2) to boost efficiency while maintaining decent generation fidelity, reducing per-step inference cost is often more effective than reducing the number of denoising steps.
- IEEE TAI
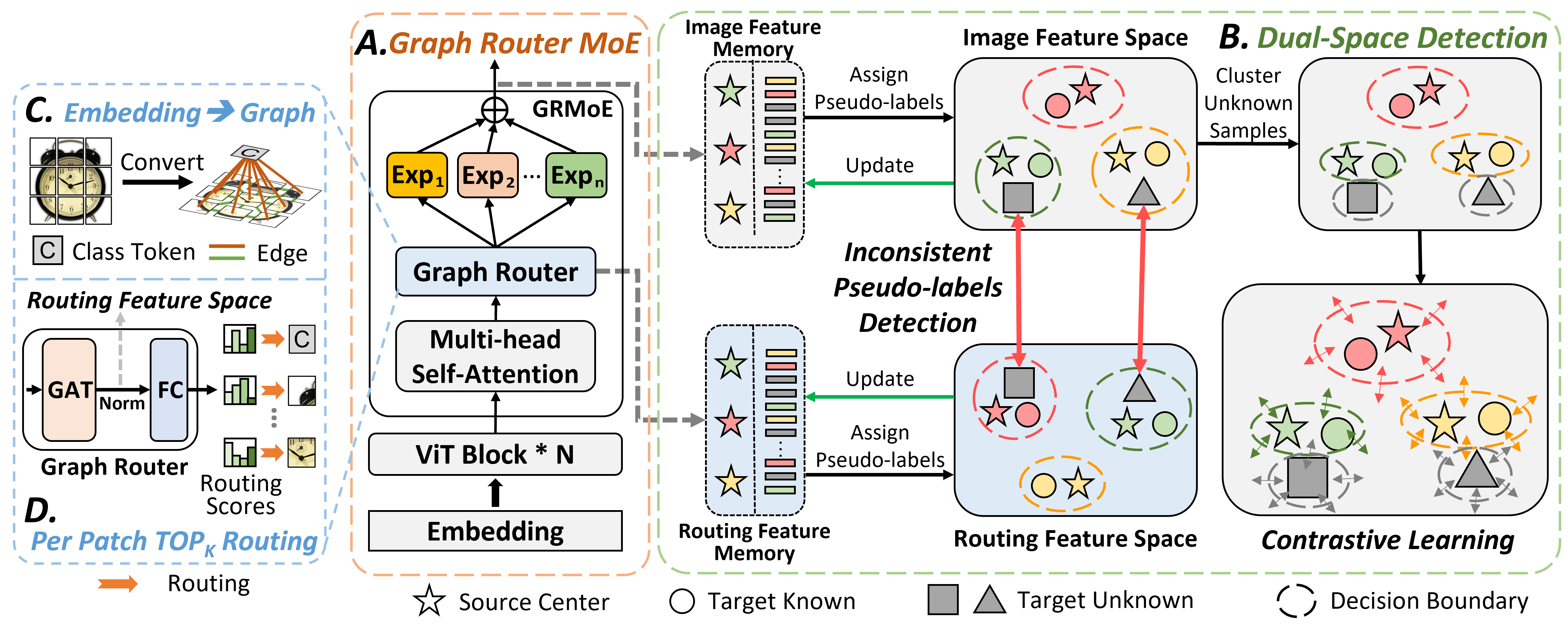 Mixture-of-Experts for Open Set Domain Adaptation: A Dual-Space Detection ApproachZhenbang Du, Jiayu An, Yunlu Tu, Jiahao Hong, and Dongrui WuIEEE Transactions on Artificial Intelligence, 2025
Mixture-of-Experts for Open Set Domain Adaptation: A Dual-Space Detection ApproachZhenbang Du, Jiayu An, Yunlu Tu, Jiahao Hong, and Dongrui WuIEEE Transactions on Artificial Intelligence, 2025Open Set Domain Adaptation (OSDA) copes with the distribution and label shifts between the source and target domains simultaneously, performing accurate classification for known classes while identifying unknown class samples in the target domain. Most existing OSDA approaches, depending on the final image feature space of deep models, require manually-tuned thresholds, and may easily misclassify unknown samples as known classes. Mixture-of-Experts (MoE) could be a remedy. Within an MoE, different experts handle distinct input features, producing unique expert routing patterns for various classes in a routing feature space. As a result, unknown class samples may display different expert routing patterns to known classes. This paper proposes Dual-Space Detection, which exploits the inconsistencies between the image feature space and the routing feature space to detect unknown class samples without any threshold. A Graph Router is further introduced to better make use of the spatial information among the image patches. Experiments on three datasets validated the effectiveness and superiority of our approach.
- CVPR 2025
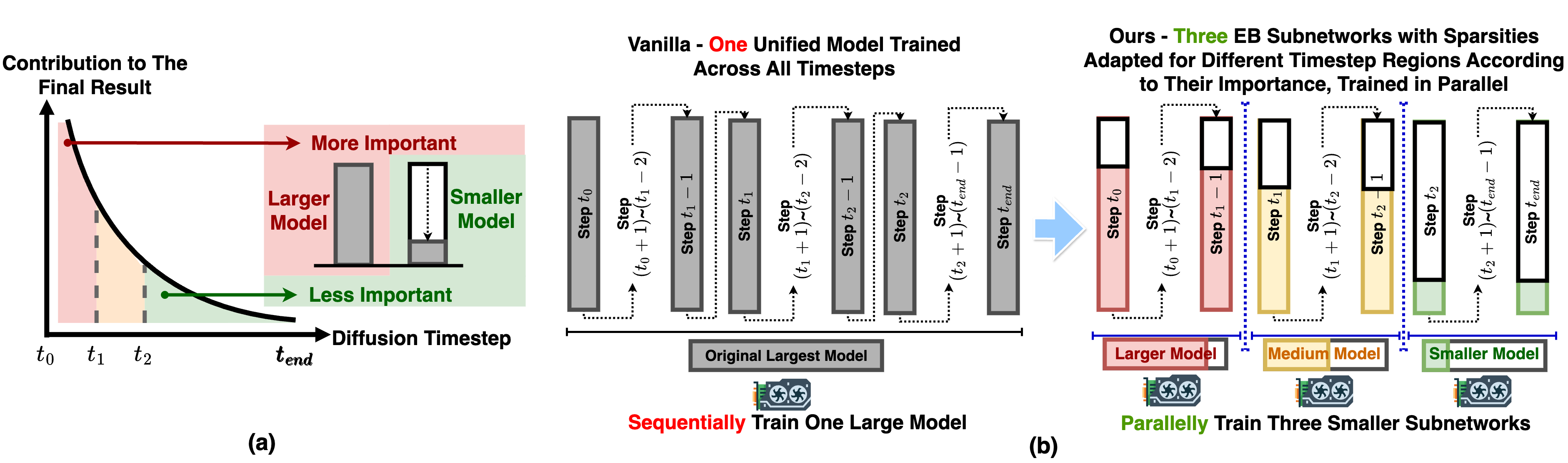 Early-Bird Diffusion: Investigating and Leveraging Timestep-Aware Early-Bird Tickets in Diffusion Models for Efficient TrainingLexington Whalen*, Zhenbang Du*, Haoran You*, Chaojian Li, Sixu Li, and Yingyan LinIn Proceedings of the Computer Vision and Pattern Recognition Conference, 2025
Early-Bird Diffusion: Investigating and Leveraging Timestep-Aware Early-Bird Tickets in Diffusion Models for Efficient TrainingLexington Whalen*, Zhenbang Du*, Haoran You*, Chaojian Li, Sixu Li, and Yingyan LinIn Proceedings of the Computer Vision and Pattern Recognition Conference, 2025Training diffusion models (DMs) requires substantial computational resources due to multiple forward and backward passes across numerous timesteps, motivating research into efficient training techniques. In this paper, we propose EB-Diff-Train, a new efficient DM training approach that is orthogonal to other methods of accelerating DM training, by investigating and leveraging Early-Bird (EB) tickets–sparse subnetworks that manifest early in the training process and maintain high generation quality. We first investigate the existence of traditional EB tickets in DMs, enabling competitive generation quality without fully training a dense model. Then, we delve into the concept of diffusion-dedicated EB tickets, drawing on insights from varying importance of different timestep regions. These tickets adapt their sparsity levels according to the importance of corresponding timestep regions, allowing for aggressive sparsity during non-critical regions while conserving computational resources for crucial timestep regions. Building on this, we develop an efficient DM training technique that derives timestep-aware EB tickets, trains them in parallel, and combines them during inference for image generation. Extensive experiments validate the existence of both traditional and timestep-aware EB tickets, as well as the effectiveness of our proposed EB-Diff-Train method. This approach can significantly reduce training time both spatially and temporally–achieving 2.9x 5.8x speedups over training unpruned dense models, and up to 10.3x faster training compared to standard train-prune-finetune pipelines–without compromising generative quality.
- CVPR 2025Layer-and Timestep-Adaptive Differentiable Token Compression Ratios for Efficient Diffusion TransformersHaoran You, Connelly Barnes, Yuqian Zhou, Yan Kang, Zhenbang Du, Wei Zhou, Lingzhi Zhang, Yotam Nitzan, Xiaoyang Liu, Zhe Lin, and othersIn Proceedings of the Computer Vision and Pattern Recognition Conference, 2025
Diffusion Transformers (DiTs) have achieved state-of-the-art (SOTA) image generation quality but suffer from high latency and memory inefficiency, making them difficult to deploy on resource-constrained devices. One major efficiency bottleneck is that existing DiTs apply equal computation across all regions of an image. However, not all image tokens are equally important, and certain localized areas require more computation, such as objects. To address this, we propose DiffCR, a dynamic DiT inference framework with differentiable compression ratios, which automatically learns to dynamically route computation across layers and timesteps for each image token, resulting in efficient DiTs. Specifically, DiffCR integrates three features: (1) A token-level routing scheme where each DiT layer includes a router that is fine-tuned jointly with model weights to predict token importance scores. In this way, unimportant tokens bypass the entire layer’s computation; (2) A layer-wise differentiable ratio mechanism where different DiT layers automatically learn varying compression ratios from a zero initialization, resulting in large compression ratios in redundant layers while others remain less compressed or even uncompressed; (3) A timestep-wise differentiable ratio mechanism where each denoising timestep learns its own compression ratio. The resulting pattern shows higher ratios for noisier timesteps and lower ratios as the image becomes clearer. Extensive experiments on text-to-image and inpainting tasks show that DiffCR effectively captures dynamism across token, layer, and timestep axes, achieving superior trade-offs between generation quality and efficiency compared to prior works.
- WWW 2025CTR-Driven Advertising Image Generation with Multimodal Large Language ModelsXingye Chen, Wei Feng, Zhenbang Du, Weizhen Wang, Yanyin Chen, Haohan Wang, Linkai Liu, Yaoyu Li, Jinyuan Zhao, Yu Li, and othersIn Proceedings of the ACM on Web Conference, 2025
In web data, advertising images are crucial for capturing user attention and improving advertising effectiveness. Most existing methods generate background for products primarily focus on the aesthetic quality, which may fail to achieve satisfactory online performance. To address this limitation, we explore the use of Multimodal Large Language Models (MLLMs) for generating advertising images by optimizing for Click-Through Rate (CTR) as the primary objective. Firstly, we build targeted pre-training tasks, and leverage a large-scale e-commerce multimodal dataset to equip MLLMs with initial capabilities for advertising image generation tasks. To further improve the CTR of generated images, we propose a novel reward model to fine-tune pre-trained MLLMs through Reinforcement Learning (RL), which can jointly utilize multimodal features and accurately reflect user click preferences. Meanwhile, a product-centric preference optimization strategy is developed to ensure that the generated background content aligns with the product characteristics after fine-tuning, enhancing the overall relevance and effectiveness of the advertising images. Extensive experiments have demonstrated that our method achieves state-of-the-art performance in both online and offline metrics.
- KBSTSPT: Two-Step Prompt Tuning for class-incremental novel class discoveryJiayu An, Zhenbang Du, Herui Zhang, and Dongrui WuKnowledge-Based Systems, 2025
In real-world applications, models often encounter a sequence of unlabeled new tasks, each containing unknown classes. This paper explores class-incremental novel class discovery (class-iNCD), which requires maintaining previously learned knowledge while discovering novel classes. We consider a more realistic and also more challenging scenario, which has a small number of initial known classes and a large number of unlabeled tasks, with the additional requirement of data privacy protection. A simple yet effective approach, Two-Step Prompt Tuning (TSPT), is proposed. TSPT tackles class-iNCD through prompt tuning, which is rehearsal-free and plug-and-play, protecting data privacy and significantly reducing the number of trainable parameters. TSPT consists of two main steps: (1) novel class discovery, which initializes the classifier using uniform clustering, and uses intra- and inter-sample consistency learning to discover novel classes; and, (2) knowledge fusion, where the prompt learned in the previous step is adapted as task-specific prompt, and additional optimal prompts are selected from a prompt pool to integrate knowledge from both old and new classes. Experiments on three datasets demonstrated the effectiveness of TSPT.
- JNESparse knowledge sharing (SKS) for privacy-preserving domain incremental seizure detectionJiayu An, Ruimin Peng, Zhenbang Du, Heng Liu, Feng Hu, Kai Shu, and Dongrui WuJournal of Neural Engineering, 2025
Epilepsy is a neurological disorder that affects millions of patients worldwide. Electroencephalogram-based seizure detection plays a crucial role in its timely diagnosis and effective monitoring. However, due to distribution shifts in patient data, existing seizure detection approaches are often patient-specific, which requires customized models for different patients. This paper considers privacy-preserving domain incremental learning (PP-DIL), where the model learns sequentially from each domain (patient) while only accessing the current domain data and previously trained models. This scenario has three main challenges: (1) catastrophic forgetting of previous domains, (2) privacy protection of previous domains, and (3) distribution shifts among domains. Approach. We propose a sparse knowledge sharing (SKS) approach. First, Euclidean alignment is employed to align data from different domains. Then, we propose an adaptive pruning approach for SKS to allocate subnet for each domain adaptively, allowing specific parameters to learn domain-specific knowledge while shared parameters to preserve knowledge from previous domains. Additionally, supervised contrastive learning is employed to enhance the model’s ability to distinguish relevant features. Main Results. Experiments on two public seizure datasets demonstrated that SKS achieved superior performance in PP-DIL. Significance. SKS is a rehearsal-free privacy-preserving approach that effectively learns new domains while minimizing the impact on previously learned domains, achieving a better balance between plasticity and stability.
2024
- ECCV 2024
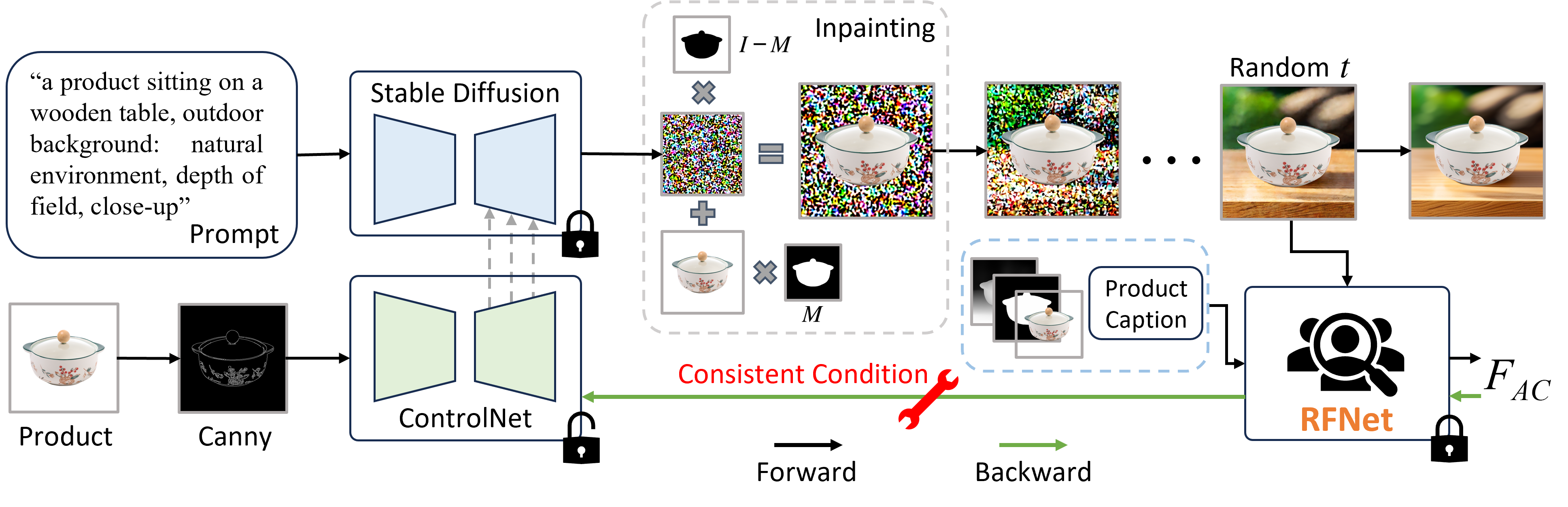 Towards reliable advertising image generation using human feedbackZhenbang Du*, Wei Feng*, Haohan Wang, Yaoyu Li, Jingsen Wang, Jian Li, Zheng Zhang, Jingjing Lv, Xin Zhu, Junsheng Jin, and othersIn Proceedings of the European Conference on Computer Vision, 2024
Towards reliable advertising image generation using human feedbackZhenbang Du*, Wei Feng*, Haohan Wang, Yaoyu Li, Jingsen Wang, Jian Li, Zheng Zhang, Jingjing Lv, Xin Zhu, Junsheng Jin, and othersIn Proceedings of the European Conference on Computer Vision, 2024In the e-commerce realm, compelling advertising images are pivotal for attracting customer attention. While generative models automate image generation, they often produce substandard images that may mislead customers and require significant labor costs to inspect. This paper delves into increasing the rate of available generated images. We first introduce a multi-modal Reliable Feedback Network (RFNet) to automatically inspect the generated images. Combining the RFNet into a recurrent process, Recurrent Generation, results in a higher number of available advertising images. To further enhance production efficiency, we fine-tune diffusion models with an innovative Consistent Condition regularization utilizing the feedback from RFNet (RFFT). This results in a remarkable increase in the available rate of generated images, reducing the number of attempts in Recurrent Generation, and providing a highly efficient production process without sacrificing visual appeal. We also construct a Reliable Feedback 1 Million (RF1M) dataset which comprises over one million generated advertising images annotated by human, which helps to train RFNet to accurately assess the availability of generated images and faithfully reflect the human feedback. Generally speaking, our approach offers a reliable solution for advertising image generation.
- IEEE TNSREMulti-branch mutual-distillation transformer for EEG-based seizure subtype classificationRuimin Peng, Zhenbang Du, Changming Zhao, Jingwei Luo, Wenzhong Liu, Xinxing Chen, and Dongrui WuIEEE Transactions on Neural Systems and Rehabilitation Engineering, 2024
Cross-subject electroencephalogram (EEG) based seizure subtype classification is very important in precise epilepsy diagnostics. Deep learning is a promising solution, due to its ability to automatically extract latent patterns. However, it usually requires a large amount of training data, which may not always be available in clinical practice. This paper proposes Multi-Branch Mutual-Distillation (MBMD) Transformer for cross-subject EEG-based seizure subtype classification, which can be effectively trained from small labeled data. MBMD Transformer replaces all even-numbered encoder blocks of the vanilla Vision Transformer by our designed multi-branch encoder blocks. A mutual-distillation strategy is proposed to transfer knowledge between the raw EEG data and its wavelets of different frequency bands. Experiments on two public EEG datasets demonstrated that our proposed MBMD Transformer outperformed several traditional machine learning and state-of-the-art deep learning approaches. To our knowledge, this is the first work on knowledge distillation for EEG-based seizure subtype classification.
- IEEE TAISemisupervised Transfer Boosting (SS-TrBoosting)Lingfei Deng, Changming Zhao, Zhenbang Du, Kun Xia, and Dongrui WuIEEE Transactions on Artificial Intelligence, 2024
Semisupervised domain adaptation (SSDA) aims at training a high-performance model for a target domain using few labeled target data, many unlabeled target data, and plenty of auxiliary data from a source domain. Previous works in SSDA mainly focused on learning transferable representations across domains. However, it is difficult to find a feature space where the source and target domains share the same conditional probability distribution. Additionally, there is no flexible and effective strategy extending existing unsupervised domain adaptation (UDA) approaches to SSDA settings. In order to solve the above two challenges, we propose a novel fine-tuning framework, semisupervised transfer boosting (SS-TrBoosting). Given a well-trained deep learning-based UDA or SSDA model, we use it as the initial model, generate additional base learners by boosting, and then use all of them as an ensemble. More specifically, half of the base learners are generated by supervised domain adaptation, and half by semisupervised learning. Furthermore, for more efficient data transmission and better data privacy protection, we propose a source data generation approach to extend SS-TrBoosting to semisupervised source-free domain adaptation (SS-SFDA). Extensive experiments showed that SS-TrBoosting can be applied to a variety of existing UDA, SSDA, and SFDA approaches to further improve their performance.
2023
- IEEE TNSRE
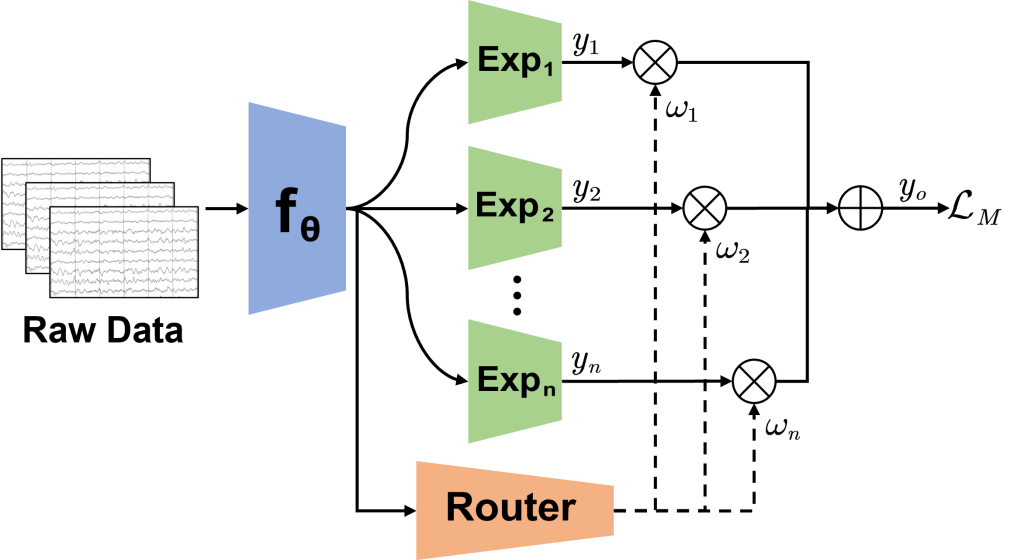 Mixture of experts for EEG-based seizure subtype classificationZhenbang Du, Ruimin Peng, Wenzhong Liu, Wei Li, and Dongrui WuIEEE Transactions on Neural Systems and Rehabilitation Engineering, 2023
Mixture of experts for EEG-based seizure subtype classificationZhenbang Du, Ruimin Peng, Wenzhong Liu, Wei Li, and Dongrui WuIEEE Transactions on Neural Systems and Rehabilitation Engineering, 2023Epilepsy is a pervasive neurological disorder affecting approximately 50 million individuals worldwide. Electroencephalogram (EEG) based seizure subtype classification plays a crucial role in epilepsy diagnosis and treatment. However, automatic seizure subtype classification faces at least two challenges: 1) class imbalance, i.e., certain seizure types are considerably less common than others; and 2) no a priori knowledge integration, so that a large number of labeled EEG samples are needed to train a machine learning model, particularly, deep learning. This paper proposes two novel Mixture of Experts (MoE) models, Seizure-MoE and Mix-MoE, for EEG-based seizure subtype classification. Particularly, Mix-MoE adequately addresses the above two challenges: 1) it introduces a novel imbalanced sampler to address significant class imbalance; and 2) it incorporates a priori knowledge of manual EEG features into the deep neural network to improve the classification performance. Experiments on two public datasets demonstrated that the proposed Seizure-MoE and Mix-MoE outperformed multiple existing approaches in cross-subject EEG-based seizure subtype classification. Our proposed MoE models may also be easily extended to other EEG classification problems with severe class imbalance, e.g., sleep stage classification.
- BSAOverview of the winning approaches in 2022 world robot contest championship–asynchronous SSVEPZhenbang Du, Rui Bian, and Dongrui WuBrain Science Advances, 2023
In recent years, the steady-state visual evoked potential (SSVEP) electroencephalogram paradigm has gained considerable attention owing to its high information transfer rate. Several approaches have been proposed to improve the performance of SSVEP-based brain–computer interface (BCI) systems. In SSVEP-based BCIs, the asynchronous scenario poses a challenge as the subjects stare at the screen without synchronization signals from the system. The algorithm must distinguish whether the subject is being stimulated or not, which presents a significant challenge for accurate classification. In the 2022 World Robot Contest Championship, several effective algorithm frameworks were proposed by participating teams to address this issue in the SSVEP competition. The efficacy of the approaches employed by five teams in the final round is demonstrated in this study, and an overview of their methods is provided. Based on the final score, this paper presents a comparative analysis of five algorithms that propose distinct asynchronous recognition frameworks via diverse statistical methods to differentiate between intentional control state and non-control state based on dynamic window strategies. These algorithms achieve an impressive information transfer rate of 89.833 and a low false positive rate of 0.073. This study provides an overview of the algorithms employed by different teams to address asynchronous scenarios in SSVEP-based BCIs and identifies potential future avenues for research in this area.
2022
- IEEE TNNLSA transfer learning-based method for personalized state of health estimation of lithium-ion batteriesGuijun Ma, Songpei Xu, Tao Yang, Zhenbang Du, Limin Zhu, Han Ding, and Ye YuanIEEE Transactions on Neural Networks and Learning Systems, 2022
State of health (SOH) estimation of lithium-ion batteries (LIBs) is of critical importance for battery management systems (BMSs) of electronic devices. An accurate SOH estimation is still a challenging problem limited by diverse usage conditions between training and testing LIBs. To tackle this problem, this article proposes a transfer learning-based method for personalized SOH estimation of a new battery. More specifically, a convolutional neural network (CNN) combined with an improved domain adaptation method is used to construct an SOH estimation model, where the CNN is used to automatically extract features from raw charging voltage trajectories, while the domain adaptation method named maximum mean discrepancy (MMD) is adopted to reduce the distribution difference between training and testing battery data. This article extends MMD from classification tasks to regression tasks, which can therefore be used for SOH estimation. Three different datasets with different charging policies, discharging policies, and ambient temperatures are used to validate the effectiveness and generalizability of the proposed method. The superiority of the proposed SOH estimation method is demonstrated through the comparison with direct model training using state-of-the-art machine learning methods and several other domain adaptation approaches. The results show that the proposed transfer learning-based method has wide generalizability as well as a positive precision improvement.